
A la maison j’ai plusieurs machines : 1 NAS, 2 raspberry pi et les PC. J’ai en plus de ça quelques projets à venir (2 raspberry non utilisés)…
Le NAS est sous Openmediavault 3.x (avec une base Debian 8 donc), mes raspberries sont sur du Raspbian, je ne suis pas dépaysé quoi 🙂
Tout ça demande de l’attention ! J’ai déjà franchi un premier pas en m’installant un Grafana pour suivre les métriques intéressantes de mes serveurs, il me restait plus qu’à faire le nécessaire pour les logs !
Mon choix s’est porté sur la suite ELK, qui est tout simplement la plus connue et celle où je m’attends à avoir le plus de ressources documentaires et le moins à bidouiller au possible (apprendre / s’amuser c’est bien, passer des heures sur mon temps libre à tordre dans tous les sens les applis des autres, c’est moins bien…). Et puis, c’est tout simplement l’occaz d’apprendre sa mise en place !
Première étape : Le téléchargement
Je ne me suis pas embêté, je suis directement passé par la case « j’ajoute le dépôt » :
apt install apt-transport-https echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - apt update && apt install logstash elasticsearch kibana
Deuxième étape : Plus de téléchargements
En fait, je me suis rendu compte qu’il y a des petits nouveaux en faisant le point sur cette suite : les « Beats », qui sont tout simplement des collecteurs. En somme, ce sont ceux qui vont récupérer les informations à envoyer à Logstash (qui va les stocker dans la base Elasticsearch… et qu’on affichera avec Kibana).
Attention les yeux… !
apt install filebeats
Et oui, c’est aussi simple que ça vu qu’on a les dépôts d’ajoutés.
Étape 0 : Un petit schéma
Pour bien comprendre ce qu’on va mettre en place, un petit schéma n’est pas de trop :
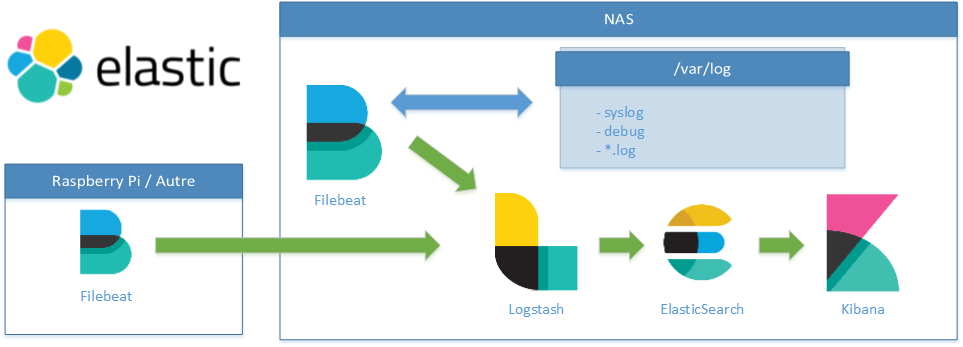
Troisième étape : La configuration…
Sources :
- https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-configuration.html
- https://www.elastic.co/guide/en/beats/libbeat/6.2/logstash-installation.html#logstash-setup
Les principaux fichiers de configuration sont assez simple à trouver sous une Debian :
/etc/<application>/<application>.yml où <application> peut être filebeat, logstash, elasticsearch ou kibana
Je commence par Filebeat (brossons ELK dans le sens du log). Après avoir sauvegardé la configuration de base, je la modifie afin d’avoir quelque chose que j’estime potable pour commencer (plein de commentaires sont présents dans le fichier de base afin de savoir ce qu’on fait, sinon -> doc officielle) :
[root@nas:/etc/filebeat]# cat filebeat.yml | grep -vE '^( *#|\s*$)'
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/*.log
- /var/log/syslog
- /var/log/debug
exclude_files: ['.gz$']
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
host: "192.168.0.253:5601"
output.logstash:
hosts: ["localhost:5044"]
Ce petit bout de config va (vous l’aurez compris normalement) récupérer les fichiers plats qui suivent le pattern /var/log/*.log, le syslog, le debug et renvoyer tout ça vers un logstash.
Attention, la syntaxe est du YAML, c’est sensible à l’indentation donc évitez les copié/collé trop sauvage (les formatage du web vont avoir tendance à casser un peu tout ça).
Si vous ne connaissez pas le YAML, c’est le moment de vous y mettre, c’est utilisé partout et ça vous sera très utile (pour faire de l’ansible par exemple).
J’ai juste changé la partie host de Kibana car par défaut, il n’écoutera que sur localhost, ce qui n’est pas souhaitable pour nous, je le règlerai donc sur une écoute sur son adresse IP dans mon sous-réseau (ici 192.168.0.253).
Du coté de Logstash, il nous faut maintenant un petit fichier de configuration (par exemple /etc/logstash/conf.d/beats-logstash.conf) qui va juste écouter sur le port défini (5044) pour une entrée de type beats et renvoyer tout ça vers un elasticsearch :
input { beats { port => 5044 } } # The filter part of this file is commented out to indicate that it is # optional. # filter { # # } output { elasticsearch { hosts => "localhost:9200" manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" document_type => "%{[@metadata][type]}" } }
La partie index et document_type seront utiles pour Kibana, pour l’instant on va laisser ça comme ça afin d’avoir une base utilisable 🙂
Ok, et maintenant ?
Et bien, nous avons donc configuré un Filebeat pour récupérer des logs du dossier /var/log et les envoyer vers Logstash, ce dernier va faire éventuellement quelque chose (SPOIL, avec notre config, il ne fait pas grand chose) et renvoyer tout ça vers ElasticSearch en spécifiant l’index et le type de document comme renseigné dans la section « output ».
La partie elasticsearch n’a pas besoin de configuration pour notre cas (pour l’instant en tout cas).
En résumé, on a de quoi stocker nos logs dans ElasticSearch ! Enfin, il faut déjà tester tout ça 🙂
Quatrième étape : Tester la configuration…
On a déjà fait pas mal de choses, même si ça semble peu, et il faut donc tester : s’assurer qu’il n’y ai pas de fautes de frappe, de fichiers avec les mauvais droits ou mal placés etc…
- Je démarre ElasticSearch :
systemctl start elasticsearch - Je lance Logstash :
systemctl start logstash - Et Filebeat :
systemctl start filebeat - Je check les logs des différents composants !
Le plus important est de voir du « filebeat » dans le log d’elasticsearch. Si c’est le cas, alors c’est gagné ! Cette première étape est validée
Il nous reste maintenant à intégrer dans elasticsearch la logique lui permettant d’analyser tout ce qui lui est remonté (c’est ce qui s’appelle tout simplement les Index Templates), dans notre cas, on doit faire ça manuellement, voir : https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-template.html#load-template-manually.
filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
Et Kibana ?
Ok, on « voit » dans les logs que ça bouge, mais c’est pas bien utile tout ça pour l’instant. Il est donc temps de sortir le « K » afin de réellement visualiser nos logs 🙂
Avant de lancer Kibana, on a un tout petit peu de configuration à faire, pour régler l’écoute sur l’interface qu’on a défini, et puis fixer un emplacement pour le pid.
Petite étape prépaparatoire du coup pour ce pid, on va créer un dossier accessible que par kibana dans /var/run :
mkdir /var/run/kibana chown kibana.kibana /var/run/kibana chmod 750 /var/run/kibana
Maintenant, le contenu de ce qui a été modifié :
[root@nas: /etc/kibana]# cat kibana.yml | grep -vE '^( *#|\s*$)' server.port: 5601 server.host: "192.168.0.253" server.name: "Mon NAS" elasticsearch.url: "http://localhost:9200" pid.file: /var/run/kibana/kibana.pid
Ok, on peut donc lancer Kibana maintenant : systemctl start kibana on lui laisse le temps de se lancer pour qu’il commence à écouter sur le port défini et on vérifie avec notre navigateur http://<ip_du_serveur>:5601
Si tout s’est bien passé, vous devriez avoir dans le coin haut-gauche de l’écran un petit bouton/lien pour récupérer les données de l’instance elasticsearch définie dans le fichier de configuration. On nous demandera alors de spécifier un pattern d’index pour ce qui est à récupérer.
Et là, c’est tout simplement ce que nous avons défini dans logstash dans cette partie index qui va nous servir (c’est le %{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}), ici on peut tout simplement lui dire de récupérer tout ce qui est filebeat-*, et lui indiquer que la date c’est le champs @timestamp
Une fois que tout ça est fait, un petit tour dans la partie « Discover » va vous permettre de visualiser tout ce qui est remonté par Filebeat, « transformé/taggé » par Logstash et stocké dans ElasticSearch.
Maintenant que Kibana est lancé, on peut intégrer tout ce qui est Dashboards définis pour les différents éléments dans cette suite (ce qui ne nous servira pas trop pour l’instant, mais qui va se compléter petit à petit) :
filebeat setup --dashboards
Cinquième étape : Les réglages
Cette dernière étape est en fait la plus importante, parce que là, on a quelque chose qui n’est pas super utile pour le coup. Moi j’aimerai bien avec des infos sur les logs NginX et avoir de jolis Dashboards. Parce que si vous avez suivi le process, on a des Dashboards, mais il ne sont pas forcément bien peuplés pour l’instant.
Vu qu’on est resté sur la suite ELK sans trop s’éloigner des réglages par défaut, on peut déjà se servir d’une partie intéressante de la suite : les plugins. Premier pro-tips, le binaire pour installer un plugin elasticsearch sous Debian est dans /usr/share/elasticsearch.
Je vais rédiger cette partie dans un autre billet, mais en attendant, voici quelques liens pour la suite :
- https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules-quickstart.html
- https://www.elastic.co/guide/en/beats/filebeat/6.2/filebeat-module-nginx.html
A suivre !